检索增强生成(RAG)

概述与动机
检索增强生成(Retrieval-Augmented Generation,RAG)*是一种结合了检索模块和生成模块的技术框架,用于增强大型语言模型的知识获取与生成能力。在RAG体系中,模型在回答问题或生成文本时,**首先从外部大规模知识库中检索相关的信息**,然后将检索到的内容作为条件输入生成器以产出最终回答。相比于传统纯参数化的语言模型(将知识全部编码在模型权重中),RAG利用非参数化的知识库,允许动态更新和迭代新知识。这样,模型可以避免为每个任务都重新训练,同时通过附加最新的知识库来*提高回答的准确性和时效性。实践证明,RAG在知识密集型任务(如开放域问答、信息检索、事实核查等)中表现优异,可以明显降低幻觉生成**概率并提升生成内容的可信度。
RAG方法的核心动机在于:大型语言模型(LLM)虽然具有强大的泛化能力,但难以涵盖所有领域知识,且无法随时更新已学知识。通过引入检索模块,RAG将语言模型的问答过程拆分为“检索(Retrieve)→生成(Generate)”两步。对于用户的查询,检索器查找知识库中的相关文档,再将这些文档作为额外上下文供生成器使用,从而使回答“信息更丰富、更准确、更可靠”。这种机制本质上让模型像“有了教科书在手”,在回答问题时能引用外部知识。同时,由于外部知识库可以频繁更新,RAG系统能够快速适应新出现的信息,解决了纯微调方案需要大量重训练的问题。
RAG 与其他范式对比
在提升大型模型能力的技术路径中,RAG与模型微调(Fine-Tuning)*和*长上下文扩展(Long-Context LLMs)等方法各有利弊。与微调相比,RAG无需调整模型参数,而是将知识库作为可更新的“知识源”输入模型。因此,RAG适用于需要动态检索最新信息的场景,而微调更适用于让模型“内化”特定格式或风格的知识。例如,RAG提供模型一 “教科书”,使其根据查询检索信息回答具体问题,而微调则像让学生通过大量学习掌握知识。RAG的优势在于可追溯性高**:每个回答都可对应到具体的知识来源,减少“凭空生成”的风险;而微调后的模型往往像“黑盒”,难以解释回答依据何在。此外,RAG通过外部知识库可持续更新信息,避免微调模型面临知识陈旧的问题。
然而,微调的好处在于能够对模型进行行为和风格的细粒度定制,例如强调领域内语法风格或特定任务结构。微调后模型在面对熟悉领域时响应更快速、连贯,但处理频繁变化的数据时需要反复重训。总的来说,RAG与微调并非互斥:实践中可将两者结合,在保持模型灵活性的同时通过微调适配特定任务。
相比之下,长上下文模型指具有超大上下文窗口的LLM,如最新的Gemini-1.5、GPT-4等,它们可以直接处理非常长的输入文本。近期研究发现,当资源充分时,长上下文LLM在整体性能上常常超过RAG。原因在于长上下文模型能从原始文本中直接捕获更多关联信息,无需检索步骤。但它们的资源需求和成本也更高。研究指出,长上下文模型在性能上略优,而RAG则显著降低了计算代价。这提醒我们,在实际应用中需要权衡:如果可以承担昂贵计算成本,长上下文模型可直接处理大篇幅信息;而对成本敏感或需要处理动态知识时,RAG仍然是一种高性价比的方案。
RAG 整体流程与架构
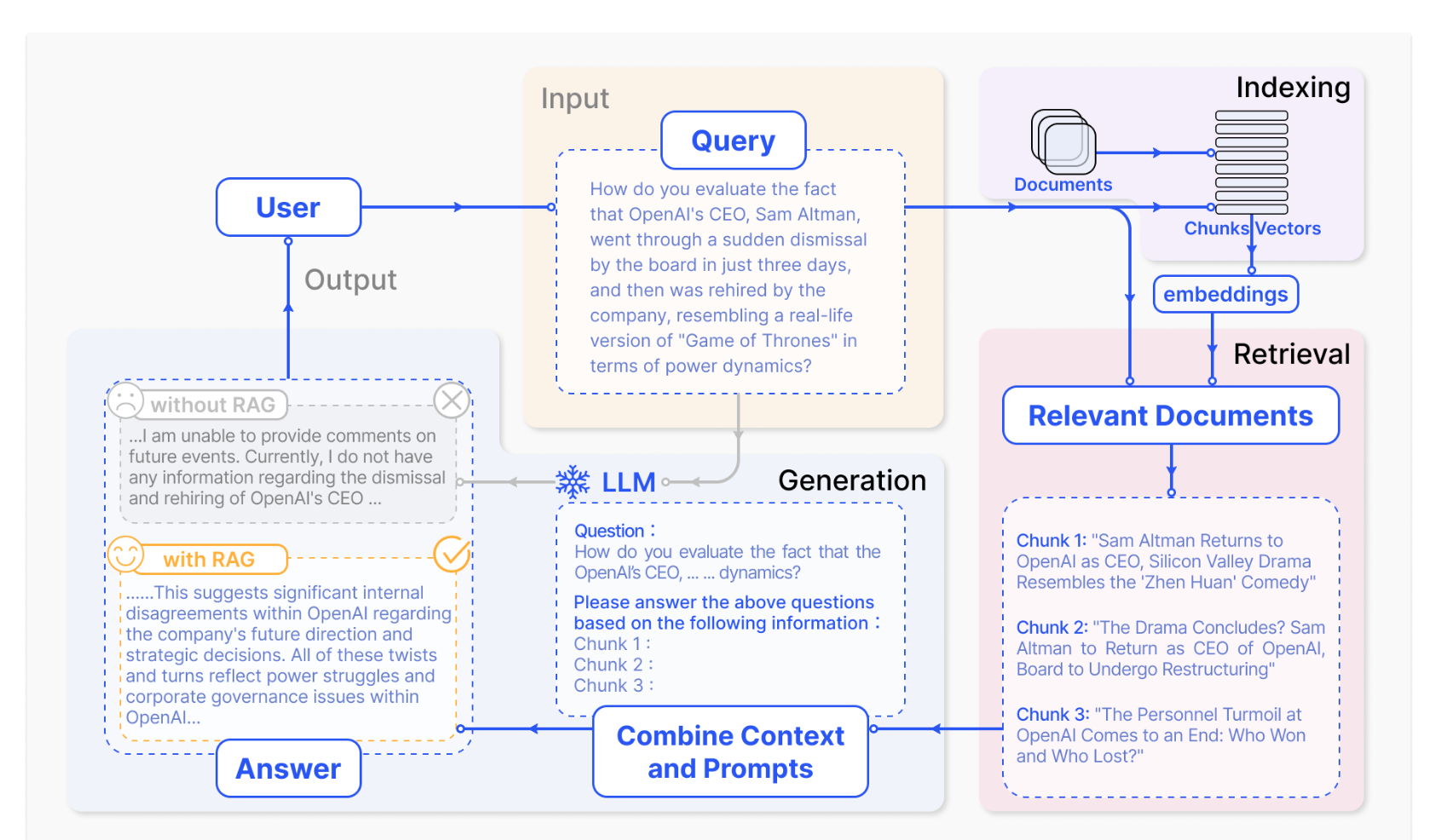
RAG系统的整体流程一般包括离线索引、在线检索和生成回答三个主要阶段,如下图所示:
- 离线索引(Indexing):在这个阶段,系统从各种数据源(文档库、数据库、网页等)提取原始文本,并对其进行清洗和预处理。通常步骤包括:(1)数据清洗与文本化——将PDF、HTML、Word等格式统一转换为纯文本;(2)切块(Chunking)——将长文档分割为适合模型处理的小段落;(3)文本嵌入与索引构建——使用嵌入模型(如BERT、text-embedding-ada-002等)将每个文本块编码为向量,并构建向量索引(如Faiss、HNSW等)以支持高效检索。这些步骤确保离线阶段完成知识库的准备工作,为检索阶段提供基础。
- 在线检索(Retrieval):当用户提出查询时,系统首先将查询进行编码,然后在向量索引中搜索与查询向量相似度最高的前K个文档片段(Top-K检索)。检索技术可以多样化:传统方法包括BM25关键词匹配,现代方法则普遍采用稠密检索(如DPR、ColBERT等)。此后,检索到的若干相关文档将作为生成器的附加上下文。在高级RAG中,还可对初步检索结果进行重新排序或筛选,以提升最终结果质量。
- 生成回答(Generation):在生成阶段,语言模型(如GPT、T5等)同时接收用户查询和检索到的相关文档作为输入,并生成最终文本回答。这个过程类似于传统的文本生成,但附加了额外的条件上下文,使模型能够引用检索到的事实信息,提高回答的准确性和丰富度。生成阶段还可能包括后处理步骤,如过滤、精简、格式化等,以输出用户期望的最终结果。
以上流程中,检索模块与生成模块相互配合,形成一个端到端的RAG体系。整个过程既保留了模型强大的语义生成能力,又引入了外部知识保障回答的真实可靠。
RAG 的发展阶段
根据研究演进,可将RAG的发展分为三个阶段:朴素RAG(Naive RAG)、**进阶RAG(Advanced RAG)**和**模块化RAG(Modular RAG)**。下图展示了RAG研究的大致时间线(资料来源:Tongji-KGLLM Survey):
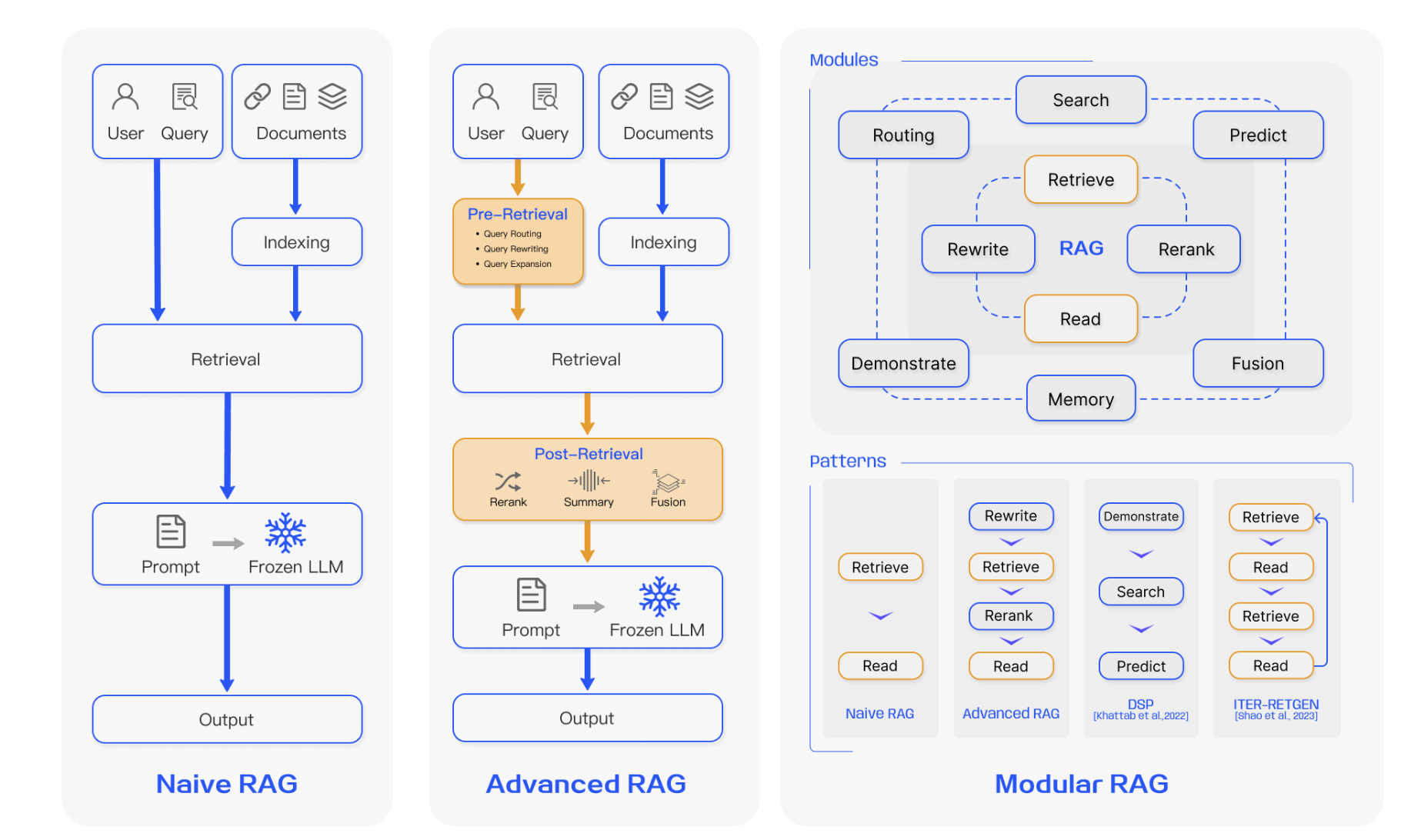
- 朴素RAG:这是在LLM普及后最早流行的RAG范式。朴素RAG按照最基本的“索引→检索→生成”流程实现,将知识检索功能直接集成到生成过程中。其特点是实现简单、可复现:在离线阶段构建知识库索引,在线阶段只执行向量检索并将结果拼接到Prompt中让语言模型生成回答。例如,Ma 等人将该过程称为“检索-阅读(Retrieve-Read)”框架。然而,朴素RAG也存在缺陷:它通常直接将检索结果原样提供给生成器,缺乏精细的内容提炼;检索结果可能包含冗余或不相关信息,导致回答准确度受限。
- 将外部文本切分为固定长度的 chunks,编码为向量并存入向量数据库;
- 将用户查询同样编码为向量,计算相似度并取 Top‑K;
- 将原始查询与检索到的片段拼接成 prompt 输入 LLM,生成答案。
该流程简单易用,但在检索精度、生成一致性与多文档融合上存在不足。
- 进阶RAG:针对朴素RAG的问题,在近年提出了一系列改进方法。进阶RAG主要在检索前后引入优化策略和微调,以提升整体效果。例如,在索引阶段通过滑动窗口、细粒度分段、图结构索引、元数据标注等手段改善文档切块与索引;在检索阶段使用更强的嵌入模型或针对任务微调嵌入模型,并通过LLM生成伪文档(如HyDE)或查询重写技术来改善查询质量;在检索后处理中加入结果再排序(如Filter-Ranker, Prompting Reranking)以及信息压缩(如训练提取摘要的PRCA、对比学习的RECOMP)等操作,使输入生成器的内容更聚焦。进阶RAG的方法较为多样,但本质目标是一致的:在原有流程中增加智能优化模块,提高检索与生成的质量与效率。
- 预检索:通过细粒度切分、滑动窗口、元数据过滤与查询重写等手段提升检索质量;
- 后检索:对检索结果进行重排序、摘要压缩或上下文筛选,减少冗余信息、突出关键内容。
这些改进在工具链如 LlamaIndex、LangChain 中已有成熟实现。
- 模块化RAG:这是最新提出的研究趋势,将RAG流程拆解成多个可替换或可插拔的模块,实现高度灵活的架构。在模块化RAG框架中,除了基础的检索器和生成器,还可额外添加任务适配模块、对齐模块、验证模块等。例如,任务适配模块自动检索任务相关提示(如UPRISE、PROMPTAGATOR),增强模型在不同任务上的泛化;对齐模块通过可训练的Adapter或强化学习(如PRCA、RRR等)来优化查询与文档的匹配;验证模块(如Yu等人的ValRAG)则在检索后评估文档与查询的相关性,加强鲁棒性。模块化RAG的优势在于可根据具体需求替换或增减功能模块,使RAG系统更具可扩展性和定制性。例如,可以实施“生成-阅读”反向流程(Generate-Read),或采用“重写-检索-阅读”流程来迭代提升回答。这一阶段的研究强调“工具化”和“可组合性”,通过不同模块的灵活组合解决朴素RAG和进阶RAG的不足。
- Rewrite‑Retrieve‑Read:先由 LLM 重写查询,再检索并回答;
- Generate‑Read:用 LLM 生成上下文替代传统检索;
- Iterative/Adaptive Retrieval:模型自主判断何时检索、迭代多轮检索与生成。
模块化 RAG 在可扩展性、灵活性和与微调技术的协同上具有明显优势。
RAG 关键组件详解
RAG系统的核心由检索器(Retriever)、**生成器(Generator)**和**增强模块**组成。下面分模块介绍各部分的技术要点。
检索器(Retrieval)
检索器负责将用户查询映射到知识库中最相关的文档片段,其设计涉及语义表示、空间匹配和输出对齐等问题。主要技术点包括:
- 文本切块与索引优化:为获得准确的语义表示,首先需要合理划分文档为文本块。块过大或过小都可能降低检索效果,因此需根据内容长度、查询特点和嵌入模型的最佳粒度选取块大小。例如,Sentence-Transformer模型适合句级块,而text-embedding-ada-002在256-512 token块下表现更好。此外,可以采用滑窗重叠检索(Sliding Window)、Small2Big技术(先检索小块再扩展至大块)、摘要嵌入检索、基于图的索引(将实体关系建模为图)等方法,提高检索召回和覆盖度。这些切块与索引策略是构建高效检索器的基础。
- 嵌入模型与微调:现代RAG普遍采用预训练的向量嵌入模型(如BERT、OpenAI Embedding等)来编码查询和文档。但预训练模型往往通用性强,对特定领域和任务的语义可能不足。因此,对嵌入模型进行领域微调十分关键。例如,可以构建包含查询、对应相关文档的三元组训练集,通过监督学习或对比学习(contrastive learning)对嵌入模型进行适配。现有实践表明,特定领域语料的微调可以显著提升检索命中率。工具方面,LlamaIndex 等框架也提供了针对嵌入模型微调的接口和类,简化了这一流程。
- 查询对齐与重写:用户原始查询可能不够规范或与文档格式不匹配。为此,可利用LLM对查询进行改写(Query Rewriting),使其更适合检索。例如,HyDE方法通过引导LLM生成“假设性文档”来扩展查询语义;RRR等方法则用强化学习生成新查询以提高匹配度。此外,可在嵌入层面加入**查询适配器(Adapter)**进行微调,使查询向量更好地与文档向量对齐。SANTA等工作则通过结构化预训练增强模型识别结构化数据。这些技术帮助缩小查询和文档语义空间的差距,提高检索的相关性和准确度。
- 检索结果优化:即使嵌入和对齐做得很好,检索器仍可能返回不完全符合LLM需求的结果。为此,可通过LLM监督微调或**重排序(Reranking)**等方法进一步优化输出。一类方法是利用LLM自身对检索结果的偏好信号来微调检索器,如AAR方法通过评估LLM对文档的关注度来生成偏好信号。另一类是通过提示将小语言模型(SLM)和大模型结合,例如“Filter-Ranker”策略使用小模型过滤初步结果,再让LLM重新排序剩余文档。最终目标是将最相关的信息提前,减少LLM处理冗余内容,从而提升整体回答质量和效率。
在 RAG 中,检索模块负责从外部知识库中获取与查询最相关的信息片段,其效果直接影响生成质量与效率。主要包括以下几个子部分:
- 检索源(Retrieval Source)
RAG 可利用多种知识源,包括:- 非结构化文本:如维基百科、行业报告、论坛帖子;
- 半结构化/结构化数据:如PDF 文档、表格、知识图谱;
- 自生内容:LLM 事先生成的摘要或中间产物。
不同源的异构结合能覆盖更广的领域背景和数据类型。
- 检索粒度(Retrieval Granularity)
- Token/句子级:可捕捉微观语义但上下文信息有限;
- 段落/Chunk 级:常用,将文本切分为固定长度(如512字)或基于语义分段;
- 文档级:直接检索整篇文章或章节,适于场景上下文完整性要求高的任务;
- 子图/命题级:针对知识图谱,多跳查询,支持深层推理。
细粒度能提升精度,粗粒度有助于保持语义连贯性,需要根据任务平衡权衡。
- 索引优化(Indexing Optimization)
- Chunking 策略:滑窗(sliding window)、句法边界切分;
- 元数据关联:对每个文档片段附加时间戳、主题标签、来源可信度等;
- 分级/结构化索引:将大文档先摘要,再对摘要建立索引,二次检索时可定位到具体段落;
- 混合检索(Hybrid Retrieval):并行使用稀疏检索(BM25)与密集向量检索,提高召回与精确度。
- 查询优化(Query Optimization)
- 查询重写(Query Rewriting):通过 LLM 对原始问题进行同义转换或细化;
- 查询扩展(Query Expansion):加入领域关键词或同义词集合;
- 查询路由(Query Routing):先分类问题,再将其路由到最相关的子知识库或子检索器;
- 子问题拆解:对复杂长问进行分步检索,每步聚焦单一子问题。
- 嵌入模型(Embedding)
- 预训练模型:如 OpenAI Ada、Sentence-BERT;
- 微调嵌入:在领域语料上继续训练,使向量更贴合专业术语;
- 双塔 vs 单塔:双塔模型(dual encoder)查询与文档并行编码,单塔模型(cross encoder)用于重排序;
- 反馈强化:利用用户点击或 LLM 评分反馈,不断优化检索模型。
生成器(Generation)
生成器负责将检索到的内容与查询融合后生成自然语言回答,核心在于如何有效利用额外上下文。主要策略包括:
- 后检索处理:检索结果可能包含大量信息,直接输入可能超出LLM的上下文容量或引入噪声。因而需要对检索到的文档进行信息精炼和筛选。例如,PRCA和RECOMP 等方法通过训练信息抽取或对比学习技术,将冗长文档压缩为关键信息摘要。同时,可减少文档数量,如“Filter-Ranker”范式中,SLM对易混淆的样本进行过滤,LLM则负责最终排序以保留最重要内容。这类处理能减轻LLM上下文负载,提高生成准确性。
- 联合编码与双编码:在Fine-Tuning阶段,通常会使用监督学习使生成器更好地融合查询和文档。在**联合编码(Joint Encoder)方案中,查询和检索到的文档一起输入至一个Encoder-Decoder模型的编码器,然后解码器通过注意力机制交叉融合这些信息生成答案。而双编码(Dual Encoder)**方案则为查询和文档分别建立独立编码器,再由解码器对两部分编码向量进行联合处理。这两种架构在训练时都会使用自回归损失进行优化。它们使模型在学习上下文扩充的同时,避免了训练时信息的不对称,让生成器更熟悉如何结合额外知识。
- 对比学习与强化:为了进一步提高生成质量,可以在训练中引入对比学习或强化学习信号。例如,SURGE等方法利用对比学习,使模型区分正确和错误的交互对,从而减轻“暴露偏差”问题。还有工作通过让LLM对生成结果进行打分作为强化信号,引导模型产生更符合预期的回答。总体来说,这些技术旨在提升生成器对多样输入的适应性和生成结果的准确性。
生成阶段接受原始查询与检索到的上下文片段,构造 prompt 并生成最终答案,关键在于如何有效利用检索结果并控制生成过程。
- 上下文策展(Context Curation)
- 重排序(Reranking):利用 cross‑encoder 对 Top‑K 结果精排,过滤无关或重复内容;
- 上下文压缩(Context Compression):对检索片段进行摘要或抽取关键信息,保证 prompt 长度受限且信息密集;
- 多文档融合:对来自不同文档的片段做多轮融合,解决内容冲突和冗余问题。
- Prompt 构建
- 模板化:根据任务类型(问答、摘要、对话)设计固定模板,保持输入结构一致;
- 动态拼接:将查询与各片段按优先级顺序拼接,中间可加入过渡句或说明性提示;
- 控制标记:使用模型特定控制符号(如特殊 token)指示何时只使用检索信息、何时可调用内参知识。
- LLM 微调与对齐(Fine‑Tuning & Alignment)
- 领域微调:使用本地或开源 LLM,根据领域 QA 对微调生成模型,提升行业适配度;
- 格式/风格适配:微调使输出符合公司文档标准或品牌语气;
- 强化学习(RLHF):通过人工或自动化评估结果打分,进一步优化生成质量;
- 知识蒸馏(Distillation):将大模型知识蒸馏到轻量模型,加速推理同时保留核心能力;
- 联合微调:同时对检索器与生成器进行协同训练(如 RA‑DIT),对齐二者偏好。
增强模块(Augmentation)
增强模块指在RAG体系中向模型注入额外知识或能力的技术,可以发生在预训练、微调或推理阶段。关键方向包括:
- 预训练阶段的增强:一些工作将检索思想引入模型预训练过程。例如,REALM利用“检索-预测”的方式在预训练中融入知识;RETRO引入外部检索器,在GPT结构中添加检索编码器和跨注意力层,从而大幅提升模型困惑度表现;Atla和COG等通过构建检索机制或复制片段的方式,让预训练模型学习检索相关的生成路径。这些方法使得模型本身就具备一定的检索能力,提升了整体知识覆盖度。
- 下游增强策略:在微调或推理时,RAG系统还会通过加入特定的增益模块来增强性能。例如,针对对话应用可以结合外部知识库和上下文链;针对专业领域可通过检索领域文献来增强回答质量。此外,自检索(Self-Retrieval)方法尝试挖掘LLM自身内部的知识库,例如使用模型自身生成查询来检索自己之前的参数记忆,从而减少对外部知识库的依赖。
- 多模态扩展:RAG不局限于纯文本。在图像、音频、代码等领域已有多项研究探索“跨模态RAG”。例如,将RAG思想应用于视觉领域(如BLIP-2通过冻结图像编码器与LLM联合预训练)、音频领域(如GSS检索音频片段辅助语音识别)、代码领域(如RBPS检索相似代码片段辅助开发)等。这些工作表明,检索增强概念可推广到不同模态数据,提高对应任务的效果。
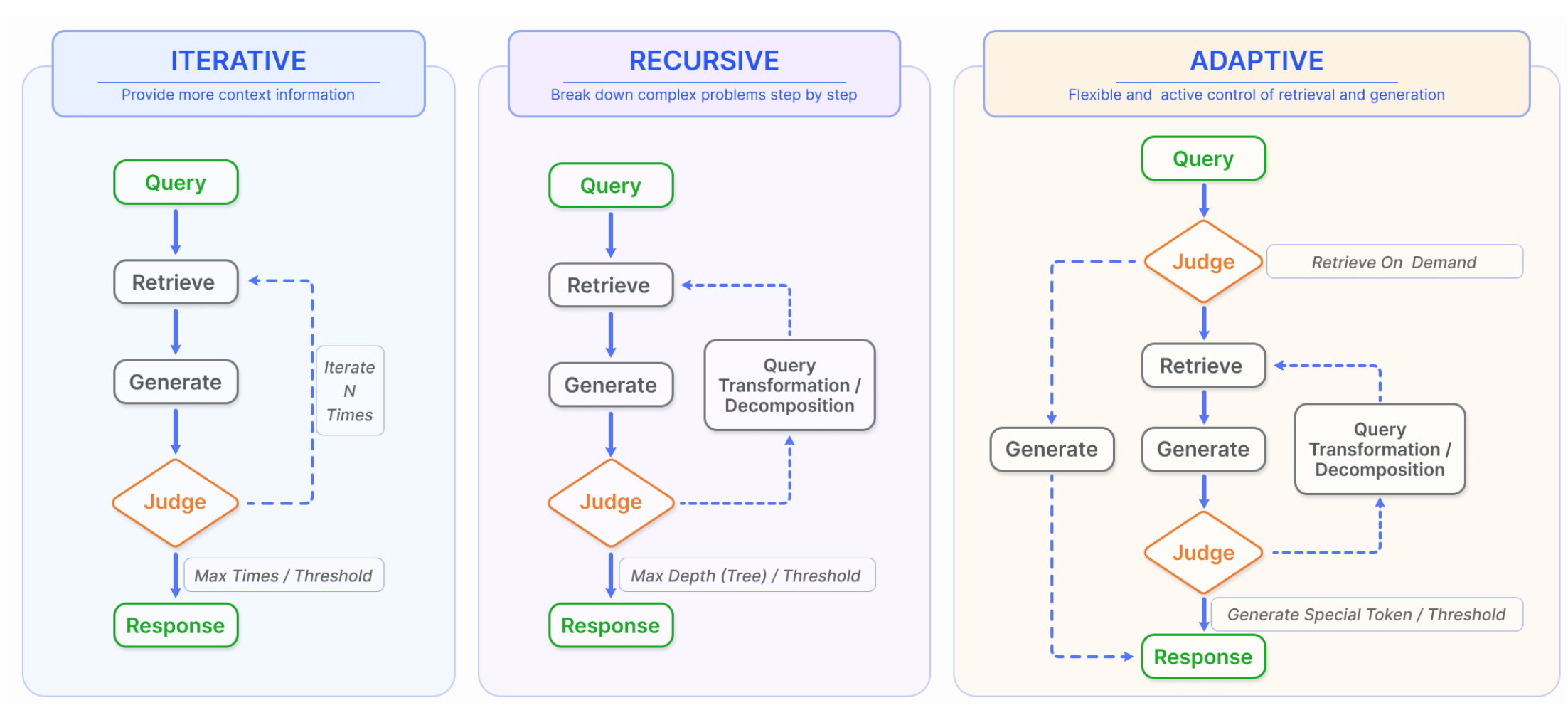
标准 RAG 流程是一次检索加一次生成,难以满足复杂推理需求。增强流程通过多种检索调度与交互策略,提供更丰富的上下文:
- 迭代检索(Iterative Retrieval)
系统交替执行“检索→生成”多轮:每轮模型基于已有生成内容扩展或细化检索,再次补充新信息,直至满足回答质量要求。ITER‑RETGEN 即为典型例子。 - 递归检索(Recursive Retrieval)
先对原始查询做拆分与重写,解决子问题后再整合答案;或先检索全局摘要,再针对高层摘要进一步检索详细信息,形成“层级式”反馈循环。 - 自适应检索(Adaptive Retrieval)
让 LLM 自主决定何时触发新一轮检索与何时终止(如通过输出特定 token 触发检索),优化检索频次与资源利用,代表方法有 FLARE、Self‑RAG 等。
RAG 与其他技术的对比
除了与微调和长上下文模型的对比外,RAG与其他提升LLM能力的范式也可以对照分析:
- Prompt Engineering(提示工程):提示工程通过精心设计模型输入提示来激发或校正模型行为,属于模型参数不变的优化策略。与RAG不同,纯提示调整只能在模型已有知识范围内发挥作用,无法像RAG那样动态引入外部知识。RAG的优势在于它为模型提供了额外的事实依据,减少了提示敏感带来的局限性。
- 持续学习与终身学习:这类方法关注让模型在上线后持续学习新知识,通常要求部分参数更新或网络结构修改。相比之下,RAG通过外部知识库实现非参数化更新,避免了频繁训练模型的高成本。因此,RAG可以看作是一种轻量级的“知识更新”手段,与昂贵的增量训练方法互为补充。
- 记忆网络与缓存机制:一些工作在模型中引入记忆组件或动态缓存,以存储历史交互或常见信息。RAG虽然也会存储知识库索引,但其检索过程通常是显式的、检索知识库进行查找,而记忆机制则更像是在模型内部维护动态历史。二者可以结合使用,例如在RAG框架中加入对话历史缓存,进一步提升连续对话场景中的回答一致性。
相关工具链
在工程实践中,已有多种工具链支持构建RAG系统,简化流程并提高效率。LangChain和LlamaIndex(前身为GPT Index)是最为流行的两大开源框架,它们提供了从数据加载、分块、索引构建到检索调用、生成回答的全套组件。例如,LangChain将整个RAG流程封装成链式调用,方便用户快速搭建问答应用;LlamaIndex侧重于灵活的数据接入,提供多种索引结构(如树形索引、向量索引、图索引等)来支撑多样化场景。矢量数据库(如Pinecone、Weaviate、Milvus等)则常被用作后端存储和检索引擎,实现海量文档的高效搜索。此外,还有Flowise、LangFlow 等低代码可视化工具,专注于使RAG开发更易操作。总体而言,这些工具链在工程落地中扮演了重要角色,使研究者和开发者能够更加专注于算法和模型本身,而无需从头实现检索流水线。
典型下游任务与评估
下游任务方面,RAG技术已广泛应用于各类知识密集型场景:
- 开放域问答:如自然问答(NaturalQuestions)、TriviaQA 等任务,通过检索对应文档并生成准确答案;
- 事实核查与信息验证:在虚假信息检测、事实核实等任务中,检索外部知识帮助模型提供证据支持;
- 文本总结:借助检索到的相关文档片段,增强生成摘要的事实覆盖度(可使用如UniEval、E-F1等指标评估);
- 机器翻译:在机器翻译中检索类似句对或术语表辅助翻译(可使用BLEU等指标);
- 代码生成和修复:检索代码示例帮助生成程序代码或自动修复缺陷;
- 对话系统:知识型聊天机器人利用RAG在对话中准确引用外部知识。
针对RAG的评估指标,除了传统生成质量评价(如准确率、BLEU、ROUGE等)外,还需关注与检索相关的指标:
- 上下文相关性(Context Relevance):衡量检索到的文档与查询的匹配程度;
- 答案准确度(Accuracy/EM/F1):评估最终回答与参考答案的正确性;
- 信息完整性与新颖性:回答是否包含必要证据,是否引入新信息;
- 可靠性与无害性:RAG答案应尽量避免错误信息和偏见。
在实践中,出现了专门针对RAG的评估框架,如RAGAS和ARES,它们从检索和生成的结合角度提出了评估指标体系(例如忠实度Faithfulness、回答相关度Answer Relevance、上下文相关度Context Relevance等)。使用这些指标可以更全面地评估RAG系统的效果。此外,还可结合人类评价或LLM自动评价来辅助判断回答质量。随着RAG技术发展,其评估工具和基准也在不断丰富,以支持不同下游任务的需求。
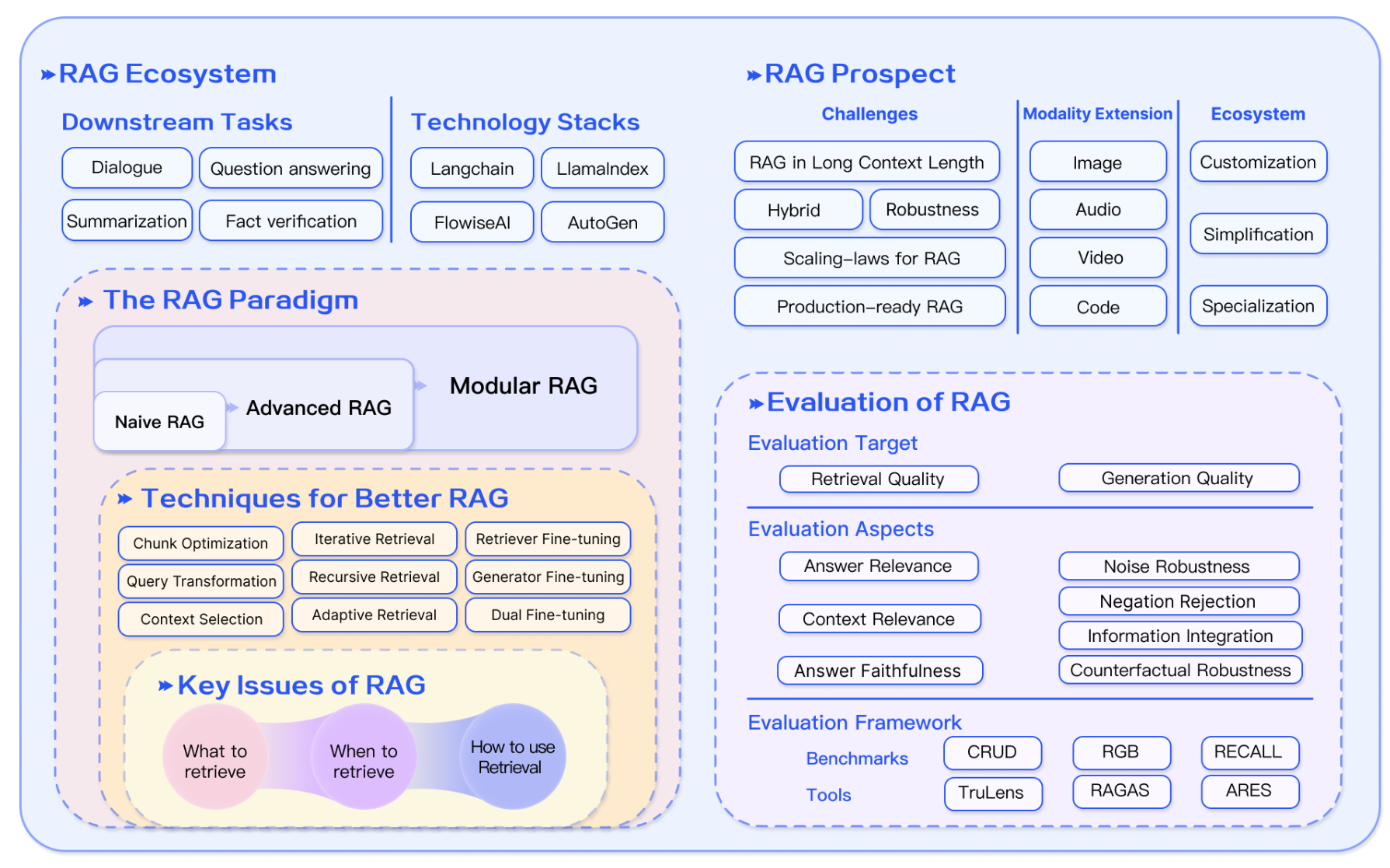
现状挑战与未来展望
尽管RAG已取得诸多成果,但仍面临挑战和发展空间。未来展望可从以下几个方面展开:
- 扩展长上下文限制:目前大多数RAG系统依赖LLM的固定上下文窗口。当检索到的信息超出模型处理能力时,需要对内容进行裁剪或压缩。如去除冗余信息或使用摘要机制。随着LLM上下文能力不断提升(如尝试支持无限长上下文),RAG如何高效协同也成为问题:一方面如何分配哪些信息需检索、哪些可直接交给模型处理?另一方面如何在极长上下文中保持知识检索的优势,是未来研究重点。
- 提升鲁棒性与安全性:检索结果中可能包含噪声或错误信息,若误导生成器就像“打开一本含毒蘑菇的书”,会严重影响RAG的有效性。因此,需要加强检索结果的验证(例如验证模块、文档事实检查)和抗噪能力。此外,企业级应用需关注数据隐私与安全,避免模型在回答时泄露知识库中的敏感元数据。
- 多模态RAG:目前的RAG研究主要基于文本,未来可向图像、音频、表格、图数据库等多模态知识源拓展。已有尝试利用视觉编码器与RAG结合(如BLIP-2对图片检索的利用)、音频检索辅助语音识别。多模态RAG能使大型模型处理更加丰富的输入类型,适用于视觉问答、视频理解等任务。
- 可解释性与透明度:RAG本身因引用外部知识带来一定解释性(可通过检索到的文档审查答案来源)。未来可以进一步开发更直观的可视化工具,展示RAG检索和生成过程中的决策链路,让用户理解答案的推理过程。此外,对模型自身行为的可解释性仍需提升,以增加用户对系统输出的信任度。
- 生态建设:随着RAG技术的普及,相关工具链和生态也在迅速发展。从系统工程角度看,RAG已经成为很多开发者搭建知识型应用的首选方案之一。未来我们可以期待更多自动化管道、开源数据集和评价基准的出现,例如用于评测RAG的端到端QA基准或事实检索挑战赛等。
总之,检索增强生成技术通过将检索机制与生成模型结合,为大型语言模型注入了可控的外部知识,显著提升了其在知识密集型任务中的表现。随着研究的深入与工程的落地,RAG有望在更广泛的场景中发挥作用,为构建更安全、可解释和通用的智能系统提供关键技术支持。
参考资料: 本文内容参考自论文《Retrieval-Augmented Generation for Large Language Models: A Survey》以及相关文献。
- Title: 检索增强生成(RAG)
- Author: KDAIer
- Created at : 2025-07-21 12:00:00
- Updated at : 2025-07-21 12:05:02
- Link: https://kcarnival.cn/2025/07/21/rag/
- License: All Rights Reserved © KDAIer