
c review

1. 格式字符串
格式字符串由普通字符(除了 % )和转换指示构成,前者被复制到输出而无更改。每个转换指示拥有下列格式:
1 | /*format testing*/ |
运行结果:
1 | 5.000000 |
2. printf 与 scanf 调用格式
printf 调用格式:
printf("<格式化字符串>", <参量表>);scanf 调用格式:
scanf("<格式化字符串>", <地址表>);
| 格式符 | 说明 |
|---|---|
| %c | 读单字符 |
| %d | 读十进制整数 |
| %l | 读十进制 Long 型整数 |
| %ll | 读十进制 Long Long 型整数 |
| %i | 读十进制、八进制、十六进制整数 |
| %e | 读浮点数 |
| %E | 读浮点数 |
| %f | 读浮点数 |
| %g | 读浮点数 |
| %G | 读浮点数 |
| %o | 读八进制数 |
| %s | 读字符串 |
| %x | 读十六进制数(其中 abcdef 小写,大写时会被忽略) |
| %X | 读十六进制数(其中 ABCDEF 大写,小写时会被忽略) |
| %p | 读指针值 |
3. 常量
3.1 整数常量
用整数前缀表示非十进制。例如:
- 二进制:前缀
0b - 八进制:前缀
0 - 十六进制:前缀
0x
用整数后缀表示无符号整数(u/U)以及长整数(l/L)。
1 | 212 /*合法的*/ |
3.2 浮点常量
浮点常量由整数部分、小数点、小数和指数部分组成,可以使用小数形式或者指数形式来表示。
- 小数形式:必须包含整数部分、小数部分,或同时包含两者。
- 指数形式:
e前面为尾数部分(必须有数),e后为指数部分(必须为整数)。
1 | 3.14159 /*合法的*/ |
3.3 字符常量
英文字母用 0-127 的整数表示,类型为 char。
常见的表示方法有两种:
- 直接表示:空格或大部分可见的图形字符
- 转义符表示:
\字符、八进制、十六进制数
| 转义字符 | 含义 |
|---|---|
| \ | \ 字符 |
| ‘ | ‘ 字符 |
| “ | “ 字符 |
| ? | ? 字符 |
| \a | 警报铃声 |
| \b | 退格键 |
| \f | 换页符 |
| \n | 换行符 |
| \r | 回车 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \ooo | 一到三位的八进制数 |
| \xhh… | 一个或多个数字的十六进制数 |
4. 存储类
存储类定义了 C 程序中变量/函数的范围(可见性)和生命周期,这些说明符放置在它们所修饰的类型之前。C 中可用的存储类包括:auto、register、static、extern。
- extern 存储类
用于提供一个全局变量的引用,全局变量对所有程序文件均可见。当有多个文件并定义了一个可在其他文件中使用的全局变量或函数时,可以使用extern来引用已定义的变量或函数。如果将其他文件的变量定义加上static,则会编译错误,因为static修饰后对其他文件不可见。
5. 变量基本类型
| 类型 | 类型标识符 | 字节 | 数值范围(十进制) | 数值范围(指数形式) |
|---|---|---|---|---|
| 整型 | [signed] int | 4 | -2147483648 ~ +2147483647 | -2³¹ ~ +2³¹-1 |
| 无符号整型 | unsigned [int] | 4 | 0 ~ 4294967295 | 0 ~ +2³²-1 |
| 短整型 | short [int](int可省略) | 2 | -32768 ~ +32767 | -2¹⁵ ~ +2¹⁵-1 |
| 无符号短整型 | unsigned short [int] | 2 | 0 ~ 65535 | 0 ~ +2¹⁶-1 |
| 长整型 | long [int] | 4 | -2147483648 ~ +2147483647 | -2³¹ ~ +2³¹-1 |
| 无符号长整型 | unsigned long [int] | 4 | 0 ~ 4294967295 | 0 ~ +2³²-1 |
| 长长整型 | long long [int] | 8 | -9223372036854775808 ~ 9223372036854775807 | -2⁶³ ~ +2⁶³-1 |
| 无符号长长整型 | unsigned long long [int] | 8 | 0 ~ 18446744073709551615 | 0 ~ +2⁶⁴-1 |
| 字符型 | [signed] char | 1 | -128 ~ +127 | -2⁷ ~ +2⁷-1 |
| 无符号字符型 | unsigned char | 1 | 0 ~ +255 | 0 ~ +2⁸-1 |
| 单精度型 | float | 4 | -3.4×10³⁸ ~ 3.4×10³⁸ | -3.4×10³⁸ ~ 3.4×10³⁸ |
| 双精度型 | double | 8 | -1.7×10³⁰⁸ ~ 1.7×10³⁰⁸ | -1.7×10³⁰⁸ ~ 1.7×10³⁰⁸ |
| 长双精度型 | long double | 8 | -1.7×10³⁰⁸ ~ 1.7×10³⁰⁸ | -1.7×10³⁰⁸ ~ 1.7×10³⁰⁸ |
[ ] 表示可省略
声明:
告诉编译器变量的名称和类型,但不一定会分配存储空间或初始化。只是告诉编译器有这个变量,可能没有分配内存。
注意: 在 C/C++ 中,带extern关键字的变量声明不会分配存储空间,而是引用已在其他地方定义的变量;某些语言(如 Java)会默认初始化变量,而 C 语言不会。定义:
除了指定变量类型外,还会分配存储空间,并可能进行初始化。变量可以有初始值,也可以没有。在 C/C++ 中,不加extern的变量声明即为定义。
1 | extern int a; // 只声明,不分配存储空间 |
1 | int a = 10; // 定义并初始化,分配存储空间 |
示例
file1.cpp
1 | int globalVar = 100; // 定义全局变量 |
file2.cpp
1 | extern int globalVar; // 声明全局变量,不分配存储 |
局部变量:
① 自动变量(动态局部变量,离开函数值消失)
② 静态局部变量(离开函数值保留)
③ 寄存器变量(离开函数值消失)
④ 形式参数(可以定义为自动变量或寄存器变量)全局变量:
① 静态外部变量(仅限本程序文件使用)
② 外部变量(允许其它程序文件引用)
注:静态变量也可归于局部变量。
| 内存区域 | 说明 | 典型分配方式 |
|---|---|---|
| 代码区 (Code Area) | 存储程序的机器指令,通常是只读的 | 编译时分配 |
| 静态区 (Static Area) | 存放全局变量和静态变量,在程序执行前分配 | 编译时分配 |
| 堆 (Heap) | 用于动态分配的内存块 | new/delete 或 malloc/free |
| 自由内存 (Free Memory) | 堆和栈之间的未分配内存空间,可供使用 | N/A |
| 栈 (Stack) | 存储函数调用的局部变量、返回地址等 | 运行时自动分配 |
6. 运算符
- 位运算优先级:
由高到低依次为:~→<<、>>→&→|→^。
位运算对象只能是整型(int)或字符型(char)数据,运算是对每个二进制位分别进行。(下表优先级从高到低)
| 类别 | 运算符 | 结合性 |
|---|---|---|
| 后缀 | () [] -> . ++ -- |
从左到右 |
| 一元 | + - ! ~ ++ -- (type) * & sizeof |
从右到左 |
| 乘除 | * / % |
从左到右 |
| 加减 | + - |
从左到右 |
| 移位 | << >> |
从左到右 |
| 关系 | < <= > >= |
从左到右 |
| 相等 | == != |
从左到右 |
| 位与 AND | & |
从左到右 |
| 位异或 XOR | ^ |
从左到右 |
| 位或 OR | | |
从左到右 |
| 逻辑与 AND | && |
从左到右 |
| 逻辑或 OR | || |
从左到右 |
| 条件 | ?: |
从右到左 |
| 赋值 | = += -= *= /= %= >>= <<= &= ^= |= |
从右到左 |
| 逗号 | , |
从左到右 |
6.1 三目运算符
- 条件运算符优先级低于关系运算符和算术运算符,但高于赋值符。
- 结合方向是自右至左。
1 | a>b ? a : c>d ? c : d; |
6.2 按位与的实际用途
- 清零:
将某个数的某个比特清零。
例如:有数00101011,若想将其右数第 4 位清零,可构造一个数11110111(对应位为 0,其余为 1),然后进行按位与运算。
1 | 00101011 |
- 取特定位:
例如:取两字节整数a=(16a1)16的低字节,构造b=(00ff)16=(255)10,然后a & b即可。
1 | 0001 0110 1010 0001 (16A1)₁₆ |
6.3 异或的实际用途
- 翻转特定位:
例如:将01111010的低 4 位翻转,与00001111异或即可。
1 | 01111010 |
- 与 0 异或:
保留原值,如012 ^ 00 = 012。
1 | 00001010 |
6.4 取反的实际用途
若一个16 位整数
1 | 0000000000111101 |
但若将此程序移植到 32 位计算机上,由于整数用 4 个字节表示,想将最后一位变成 0 就不能用
因为在以 2 个字节存一个整数时, 1 的二进制形式为
7. 隐式转换
- 如果两个操作数类型不一样,则会发生隐式类型转换。
1 | complex > imaginary > long double > double > float > 整数 |
- 低等级操作数转换到高等级:
1 | 1.f + 2000000L; // long int 转 float;执行 float 加法 |
两个整数
i,j需要执行浮点除法时,可写为1.0 * i / j或(double)i / j。整数类型等级:
1 | long long > long >= int >= short > char |
- 整数提升:
若存在高于int等级的类型,则低等级操作数转换为高等级;否则都自动转换为int或unsigned int。
提升后运算时,unsigned优先:
1 | a_char + 'a' // 两个操作数均转为 int |
8. switch 语句
- 基本格式:switch结构中的” 表达式” ,其值的类型应为整数类型(包括字符类型char等)。switch下面的花括号是一个语句块,其中包含了多行以关键字case为开头的语句。每行语句case后面跟最一个常量。
1 | switch(表达式) |
- 示例:
1 | case 10: printf("..."); break; // 正确 |
9. 实数比较
在计算机中,连续实数由 float 或 double 表示,由于离散表示,存储的计算结果往往只是近似值。因此,两个实数变量不能直接使用 == 或 != 进行比较,或判断其是否为零。特别是在循环语句中使用 (x == y) 比较,可能导致不确定的死循环。实际中,实数比较一般仅使用 > 和 <,而判断相等时可使用 fabs(x-y) < eps(eps 为合适的小数,如 1e-7),判断零时可使用 fabs(x) < eps。
- 计算 PI(精确到小数点后 5 位)的示例:
1 | /*pi*/ |
10. 头文件
- 自定义的头文件使用双引号
" "包围。 - 头文件第一行使用
#pragma once指令确保只展开一次。 - 头文件扩展名为
.h。 - 头文件通常包含共享的函数声明、全局变量声明与初始化。
注意: 头文件中函数与变量不能用static修饰。
11. 最大公约数(辗转相除法)
欧几里得算法(辗转相除法)的递归公式如下:
1 |
|
12. 预处理指令
预处理指令控制预处理器行为,每个指令占据一行,必须以 # 开头。支持的指令包括:define、undef、include、if、ifdef、ifndef、else、elif、elifdef、endif、line、error、pragma。
- 条件编译示例:
1 |
|
1 |
|
文本宏:
利用#define定义标识符代表字符串;已定义的宏可用#undef撤消。
注意: 定义时不能有分号(#define N 3; //出错! ,不能有分号,宏定义N 代表3; 注意3后面有” ;”,而将“3;”代入表达式中N,当然出错! )。包含其他文件:
#include "stdio.h"(先在当前工程目录下查找)或#include <stdio.h>(按标准方式查找)。产生错误:
使用#error指令。防止头文件重复包含:
如果一个头文件被引用两次,编译器会处理两次头文件的内容,这可能产生错误。为了防止这种情况,标准的做法是把文件的整个内容放在条件编译语句中,如下:
1 |
|
13. 数组
注意数组定义时不能用变量作为长度(例如 arr[m],其中 m 为变量,必须为常量)。//m为变量,必须为常量才可以 const int m = 5;
1 | int main() |
获取数组长度:
#define LEN_ARRAY(a) (sizeof(a) / sizeof(a[0]))sizeof(array)返回数组定义的字节数。数组名:
数组名是地址值(右值),同时也是第一个元素的地址,即a == &(a[0]),因此*a == *&(a[0]) == a[0],为左值。类型隐式转换:
int a[] = {1, 2, 3.14, 4, 5}
数组元素赋零值:
memset(arr, 0, sizeof(arr))。
1 | void vadd(int a[const], const int b[], const size_t sz) |
1 | void matrix_add(int a[][3], int b[][3], size_t m){ |
- 数组形参是一个变量,可保存数组的地址,用不定长数组表示,如 b[]。如果形参定义为 int b[10], 则编译忽略数组长度。
- const 在函数申明中应用int a[const] 表示形参 a 不可修改;const int b[] 表示b的元素不可修改;const size_t sz 表示sz不可修改
- 函数中无法获得数组的长度,通常会将数组长度作为参数传给函数,类型是size_t
- 多维数组形参仅第一维用不定长数组表示,如 b[][3]。
- 如果形参定义为 int b[10][3], 则编译解释 int b[][3]。
- 多维数组形参除第一维外,长度必须是常量
14. 字符数组
在 C 语言中,字符串作为字符数组处理。关心的是字符串的有效长度(以 '\0' 为结束标志)。
1 |
|
例如,从键盘输入 “How are you?” 时,由于空格作为分隔符,实际只读入 “How” 到 str 中。
| H | o | w | \0 | \0 | \0 | \0 | \0 | \0 | \0 | \0 | \0 | \0 |
|---|
- 输入输出方式:
(1) 逐个字符使用%c;
(2) 整个字符串使用%s。
15. ASCII 码
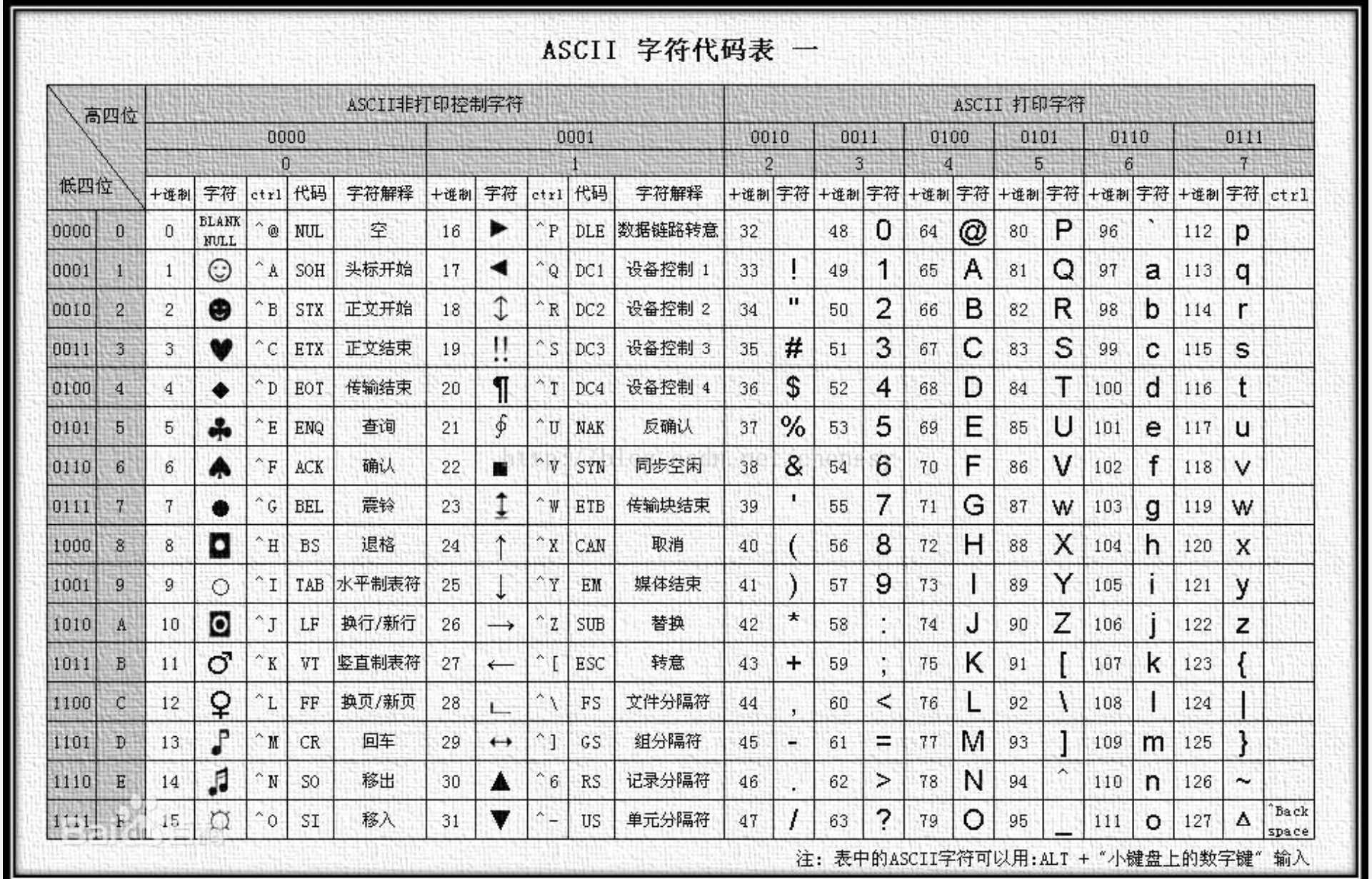
- 控制符: 共 33 个(前 32 个字符,例如 7 对应
'\t',10 对应'\n',13 对应'\r'等),127 也是控制符。 - 可打印字符: 共 95 个(例如 32 为空格,48-57 为 ‘0’… ‘9’,65-90 为 ‘A’… ‘Z’,97-122 为 ‘a’… ‘z’)。
- 空白字符: 包括空格、水平制表、垂直制表、换页、换行。
16. Unicode
Unicode 是一个字符集,是其他字符集的超集,包含来自 ISO/IEC 6937、ISO/IEC 8859 家族、Big5、KS X 1001、JIS X 0213、GB2312、GBK、GB 18030、HKSCS、CNS11643 等字符集的字符。它包含三种编码形式:
UTF-8:变长格式
UTF-16:16 位宽字符
UTF-32:32 位宽字符
单字节字符: 表示英文或西方字符,类型
char(例如'a'、'\n'或'\13')16 位宽字符: 表示中文、日文等,类型
char16_t(例如u'字',但非u'🍌')32 位宽字符: 表示 emoji 等扩展,类型
char32_t(例如U'字'或U'🍌')宽字符: 类型
wchar_t,可设定为 16 位或 32 位(例如L'β'或L'字')
17. 字符与字符串
子串: 由某个字符串中连续的一段字符组成
例如,“abcd”的所有子串为:Ø, “a”, “b”, “c”, “d”, “ab”, “bc”, “cd”, “abc”, “bcd”, “abcd”。
长度为 n 的字符串共有 n*(n+1)/2 + 1 = O(n²) 个子串。前缀: 某个字符串开头的一段子串
“abcd”的前缀为:Ø, “a”, “ab”, “abc”, “abcd”。共 n+1 个前缀。后缀: 某个字符串末尾的一段子串
“abcd”的后缀为:Ø, “d”, “cd”, “bcd”, “abcd”。共 n+1 个后缀。库函数:
Isalnum(ch)判断字符是否为数字或字母;tolower(ch)返回字母的小写形式,非字母则返回原字符。
1 | char msg[4]; |
| 操作 | 代码 | 操作 | 代码 |
|---|---|---|---|
| 输入 | scanf("%s", str); |
字符串的拷贝 | strcpy(toStr, fromStr) |
| 输出 | printf("%s", str); |
字符串的比较 | strcmp(str1, str2) / strncmp(str1, str2, n) |
| 整行输入 | gets(str); |
转换为小写 | strlwr(str) |
| 整行输出 | puts(str); |
转换为大写 | strupr(str) |
| 获取/操作第i个字符 | str[i] |
字符检索 | strchr(str, c) |
| 求字符串str长度 | strlen(str) |
字符串检索 | strstr(str1, str2) |
| 字符串的连接 | strcat(toStr, fromStr) / strncat(toStr, fromStr, n) |
字符串结束标志 | '\0'(ASCII码为0的字符) |
| 头文件 | 分类 | 常见函数 |
|---|---|---|
ctype.h |
字符分类 | isalnum, isalpha, isdigit, islower, isupper, isspace, isprint …… |
| 字符操作 | tolower, toupper |
|
stdlib.h |
转换成数值 | atof, atoi(注:itoa 是非标函数) |
string.h |
字符串操作 | strcpy, strncpy, strcat, strncat |
| 字符串检验 | strlen, strcmp, strchr, strrchr, strstr …… |
|
| 字符数组操作 | memchr, memcmp, memset, memcpy, memmove …… |
|
| 杂项 | strerror |
18. 指针
1 | /*pointer array*/ |
19. const
1 | /*const point*/ |
- 说明:
- const 限定的左值表达式只能初始化,不能赋值;
const int和int是不同类型;- 非 const 可隐式转换为 const 版本;
- const 转为非 const 必须显式转换;
- 在函数声明中,
double x[const]等价于double * const x,而const double x[]等价于const double *x。
20. 字符串字面量 —— 常指针
字符串字面量在编译阶段存放在独立资源文件中,与代码一起加载到只读代码段。
- 注意:
char *s指向只读字面量;char t[N]保存字面量的副本;- 不能修改字符串字面量;
- 相同字面量只有一份(例如
(char*){"STUDENT"} == s)。
1 | /*const string*/ |
字符串字面量数组空间不连续,只能使用指针数组或指针的指针。 每个字面量独立存放,与代码一起加载到只读代码段。
- 注意:
char *s[]与char t[][N]的初值有差异:前者指向只读字面量;后者为连续数组。 ss[] 指向只读字面量; t[M][N] 是连续的数组。- 不能修改字符串字面量,应使用
const char *ss[]。 - 相同字面量只有一份,因此
pp[0] == pp[1]。
1 | /*const string*/ |
综上:在 C 语言中,字符串字面量(如 “STUDENT”)在编译阶段就会存储在代码段(.rodata 只读数据段),并且在运行时加载到程序的只读内存区域。因此:
- 字符串字面量存储在只读内存区,不能修改(修改会导致段错误 Segmentation Fault)。
- 相同的字符串字面量在内存中只有一份,编译器会进行优化。
| 声明方式 | 存储位置 | 是否可修改 | 共享同一份内容 |
|---|---|---|---|
char *s = "STUDENT"; |
只读代码段 | ❌ 不能修改 | ✅ 共享 |
char t[] = "STUDENT"; |
栈(或静态存储区) | ✅ 可以修改 | ❌ 不共享 |
char *s[] = {"hello", "hello", "!"}; |
只读代码段 | ❌ 不能修改 | ✅ 共享 |
char sa[][10] = {"hello", "hello", "!"}; |
栈(或静态存储区) | ✅ 可以修改 | ❌ 不共享 |
核心原则:
- 字符串字面量存储在只读内存区,不能修改。
- 数组存储字符串副本,可以修改,但不共享同一份数据。
- 指针数组存储字符串字面量地址,多个指针可能指向同一块内存。
21. void* 指针
void * 类型的指针变量仅保存指针值(地址),忽略指向数据的类型,因此编译器不允许使用 * 解引用或下标运算。
它可以隐式转换为任意类型指针。
1 |
|
MemRepeat:用同类型的变量值,填充dest数组,例如:int a[10], d=7; MemRepeat(a,&d,sizeof(d),10);Printx: 打印 p 指向对象的二进制值,例如double f=3; Printx(&f,sizeof(f))。
在 <stdlib.h> 中声明了两个函数:
void* malloc(size_t size);用于分配未初始化内存void free(void* ptr);用于回收内存
注意:
malloc和free必须成对使用;- 多次
free同一指针或未释放分配的指针都会导致错误或内存泄漏。
1 | /*void-malloc-free*/ |
22. 函数指针
程序中定义了一个函数,在编译时系统就会为这个函数代码分配一段存储空间,这段存储空间的首地址称为这个函数的地址。函数名表示的就是这个地址。函数指针变量,简称函数指针,可用于存放函数参数类型、数量,及返回值类型与定义一致的函数地址。函数指针定义:函数返回值类型 (* 指针变量名) (函数参数类型列表): 𝑖𝑛𝑡(∗ 𝑝)(𝑖𝑛𝑡, 𝑖𝑛𝑡); 注意: 函数指针变量没有算术运算,下标运算 。
定义示例:
1 | // 声明一个函数 |
1 |
|
回调函数
1 | void qsort(void *base, int nelem, int width, |
调用方式有两种:
- 直接调用:在函数 A 内直接使用函数 B 的名称调用;在函数A的函数体里通过书写函数B的函数名来调用之,使内存中对应函数B的代码得以执行。
- 间接调用:使用函数指针调用。在函数A的函数体里并不出现函数B的函数名,而是使用指向函数B的函数指针来使内存中属于函数B的代码片断得以执行。
回调函数,函数指针作为某个函数的参数,由函数外部逻辑决定函数行为。例如,在排序时,将数组元素的比较逻辑交给外部传入的函数。
1 | /*selected sort callback version*/ |
| 定义 | 含义 |
|---|---|
| int i; | 定义整型变量i |
| int *p | p为指向整型数据的指针变量 |
| int a[n]; | 定义整型数组a,它有n个元素 |
| int *p[n]; | 定义指针数组p,它由n个指向整型数据的指针元素组成 |
| int (*p)[n] | p为指向含n个元素的一维数组的指针变量 |
| int f( ); | f为带回整型函数值的函数 |
| int *p( ); | p为带回一个指针的函数,该指针指向整型数据 |
| int (*p)( ); | p为指向函数的指针,该函数返回一个整型值 |
| int **p; | p是一个指针变量,它指向一个指向整型数据的指针变量 |
23. 结构体
结构体(struct)是由一系列数据成员组成的用户自定义类型。
1 | struct STUDENT { |
- 使用关键字 struct 完成类型定义等操作定义结构体类型与变量。”struct1.identifier{ 成员变量表}” 完成结构体定义。然后直接定义该类型的实例变量,注意”;”结束。
- 仅定义结构体类型变量。注意:c语言中,结构体类型是”struct STUDENT”不是”STUDENT”与C++不同。
- 仅定义结构体类型。以后再申明它的实例变量。注意:定义格式“structidentifierf members list l vars list ;” ,”}”后分号不能省。
- 习惯上 struct 标识符 用大写风格
23.1 结构体嵌套
注意:嵌套结构体中不能出现自身,否则编译会报错。如果 A 结构体中包含 B 结构体(非指针)成员,则 B 必须在 A 之前定义。
1 | struct STUDENT |
23.2 typedef 关键字
typedef 可为类型起新的别名,示例如下:
1 | typedef oldName newTypeName; |
23.3 给匿名结构体起别名
简化结构体名称,示例如下:
1 | typedef struct // 匿名结构体 |
23.4 数组类型与函数指针类型别名
1 | typedef int MATRIX_3[3][3]; // 申明数组类型别名,习惯大写风格 |
23.5 结构体实例变量与成员的操作
结构体的实例变量,成员变量都可以使用 取地址、解引用和赋值运算。其中实例变量赋值一次可复制所有成员的值,包括其中的数组类型成员 :(结构体实例是变量,而数组是地址。变量可以取地址。结构体第一个成员的地址值,一定等于该成员所属实例变量的地址值)
1 | typedef struct |
23.6 成员运算符
- 使用点运算符
.访问实例变量成员 - 使用箭头运算符
->访问指针变量成员
1 | strcpy(anna.id, "0101"); // 使用点运算符 |
1 | void readStudents(CLASS_PTR p) |
- 注意:
指针作为函数的返回值,必须保证所指对象没有被释放,因此不能返回指向函数中自动变量的指针。具体的,以下返回的指针都是安全的:- 返回指向函数中静态变量的指针;
- 返回指向函数中定义的字符串字面量的指针;
- 返回指向全局变量或函数的指针;
- 返回函数参数引用的对象及其关联对象的指针,如指向传入数组的元素,或指向传入结构体指针的成员;
- 返回动态申请内存的指针。
23.7 动态内存与结构体
使用 malloc() 申请内存保存结构体对象/变量,使用 free() 释放内存。
1 | CLASS_PTR createClass(char *name, int cnt) |
23.8 自引用结构体
结构体不能直接嵌套自身,但可以通过成员变量引用自身类型。例如: struct NODE 中有个 next 指针引用 struct NODE
1 | typedef struct NODE Node; // 预声明结构体别名 |
考虑链表的示例:
1 | struct ListNode |
24. 共用体(Union)
共用体与结构体类似,但其成员共享同一块存储空间。与结构体一样,共用体(union)也是一种派生数据类型。共用体的成员共享同一个存储空间。共用体的成员可以是任意数据类型。 可对共用体执行的操作有三种:实例变量的复制; &运算符取共用体实例变量地址, 注意:实例变量地址值和所有成员变量地址值都相等;用原点成员运算符或指针运算符访问共用体的成员。不能用运算符==或!=来比较两个共用体。
- 内存分配:
- 共用体 (union):所有成员共享同一块内存,大小由最大的成员决定。任意时刻只能存储一个成员,存储新的成员会覆盖掉之前的成员。
- 结构体 (struct):每个成员都有自己的存储空间,成员之间不会相互覆盖。结构体的总大小等于所有成员大小之和(考虑字节对齐)。
1 |
|
- 数据存储示例:
- 共用体:由于所有成员共享内存,只能存储一个成员的值,读写不同成员可能导致数据损坏。
- 结构体:各个成员独立存储,可以同时存储多个值,互不干扰。
1 |
|
注:赋值 d.f 后会覆盖 d.i 的值。
25. 枚举类型
枚举类型通过关键字 enum 定义,用标识符表示的整型枚举常量集合。
默认枚举值从 0 开始递增,也可显式赋值。
1 | enum month {january, february, march, april, may, june, july, august, september, october, november, december}; // 0-11 |
在一个枚举类型中,标识符必须唯一。多个成员可以拥有相同的常量值。
1 |
|
1 |
|
26. 结构体对齐
在 32 位计算机中,CPU 加法一次处理 32 位数(4 个字节)。大于字宽的数据通常按 4 字节对齐。32位计算机指 CPU 加法指令一次完成 32 位数加法。字宽指 CPU 一次从访问内存读或写的位数, 32位字宽表示一次读或写4个字节。 对齐(alignment)。例如大于字宽的基本类型数据都按字宽边界对齐,即使浪费一些内存也值得。因此,程序中整数变量地址一般是 4 的倍数。
预编译指令:
#pragma pack(N)控制后续定义的类或联合体的最大对齐值。字宽 32 默认 𝑁 = 4。 𝑁 ∈ {1, 2, 4, 8, 16, 32}基本数据类型:
数据类型所占字节数 ≥ N,则地址为 N 的倍数;< N,则对齐为数据类型本身的大小。例如 char 类型对齐值是1,开始地址是1的倍数 ;short 开始地址是2的倍数; int 开始地址是4的倍数。结构体:
对齐值为成员中最大对齐值与 N 的最小值,且size也必须是该对齐值的倍数。
1 | /*struct layout*/ |
1 | /*union layout*/ |
27. 位域
位域可以使得结构体支持方便的按位访问 。用于精确控制变量的二进制位数,从而节省存储空间。
1 | struct 结构体名 { |
27.1 位域对齐
若多个位域连续定义,则会被打包在一起。
注意: 第一个位域必须按整数对齐,一个包最多为一个整数。
1 | struct Example { |
27.2 匿名位域
匿名位域用于跳过若干位;0 宽度位域表示当前整数包已满,下一个位域分配在新整数单元。
位域不能取地址,建议与 union 配合使用。
1 |
|
内存分配说明:
| 变量 | 位域大小 | 存储范围 | 说明 |
|---|---|---|---|
a |
3 位 | 第 0-2 位 | 位域拼合 |
匿名位域 :5 |
5 位 | 第 3-7 位 | 跳过,不能访问 |
b |
4 位 | 第 8-11 位 | 位域拼合 |
:0 |
对齐 | 新 unsigned int | 强制对齐到新整数 |
C |
4 位 | 新 int 的第 0-3 位 | 单独占据一个 int |
1 | sizeof(struct Example) == 8 |
(两个 unsigned int,每个 4 字节,总计 8 字节)
27.3 类型总结
| 数据类型 | 分类 | 说明 | 例子 |
|---|---|---|---|
| 基本类型 | 整型 | 存储整数 | int (-32768~32767) |
| 字符型 | 存储单个字符(ASCII 编码) | char |
|
| 实型(浮点型) | 存储小数(单精度和双精度) | float, double |
|
| 构造类型 | 数组 | 一组相同类型的数据 | int arr[10] |
| 结构体 | 组合多个变量形成新类型 | struct |
|
| 联合体 | 共享内存的变量结构 | union |
|
| 枚举 | 一组命名的整数值 | enum |
|
| 指针类型 | 指针 | 存储地址的变量 | int *p |
| 空类型 | void | 无返回值或泛型指针类型 | void |
| 说明 | 字符型 | 短整型 | 整型 | 长整型 | 单精度浮点型 | 双精度浮点型 |
|---|---|---|---|---|---|---|
| 数据类型 | char | short | int | long | float | double |
| 长度 | 1 | 2 | 4 | 4 | 4 | 8 |
28. 文件定义
从数据视角看,文件分为两大类:
文本文件 (text):
由 ASCII 码及其扩展字符构成的文字序列。可用记事本、Sublime、VS Code 等文本编辑软件打开。
具有编码属性(如 ASCII、ANSI、GBK、BIG5、UTF-8 等)。
若包含 EOT(4)、STX(3)、-1 等控制符,可能导致传输中止。二进制文件:
以字符数组形式存放数据,每类应用有特定数据格式(如.zip、.obj等)。
通常直接将内存数据原样写入文件(例如整数以 4 字节补码形式存储),保存struct时需考虑 packed 或 unpack。
从应用角度,文件可分为:
- 输入流 (stream): 数据通过管道流入应用;
- 输出流: 数据从应用流出。
- 输入输出设备: 如磁盘既能产生输入流又接受输出。
从操作角度,文件操作由操作系统提供:
- 打开文件: 通过文件名建立流机制。
- 操作文件: 读写数据。
- 关闭文件: 释放文件占用资源。
29. 文件操作
头文件
<stdio.h>:
包含与操作系统交互的函数和数据结构。- 结构体 FILE: 描述 IO 流信息,通常使用
FILE *指针操作。 - 标准流:
stdin:标准输入(键盘)stdout:标准输出(显示设备)stderr:标准错误输出
- 结构体 FILE: 描述 IO 流信息,通常使用
常用函数:
- 文件访问:
fopen、fclose、freopen、fflush等 - 直接 I/O:
fread、fwrite - 无格式 I/O:
fgets、fputs、fgetc/getc、fputc/putc、ungetc - 标准 I/O:
getchar、putchar、gets、puts、scanf、printf - 格式化 I/O:
fscanf、fprintf - 字符串 I/O:
sscanf、sprintf - 文件位置:
fseek、gtell、fgetpos、fsetpos、rewind - 错误处理:
clearerr、feof、ferror、perror - 文件操作:
remove、rename、tmpfile、tmpnam - 宏常量:
EOF
- 文件访问:
示例: 格式化文本通常描述一个数据条目(如学生信息),数据域之间用空白字符分隔;无格式文本先读入内存再处理。
1 | /*file copy*/ |
| 文件访问模式字符串 | 含义 | 解释 | 若文件已存在的动作 | 若文件不存在的动作 |
|---|---|---|---|---|
| “r” | 读 | 打开文件以读取 | 从头读 | 打开失败 |
| “w” | 写 | 创建文件以写入 | 销毁内容 | 创建新文件 |
| “a” | 后附 | 后附到文件 | 写到结尾 | 创建新文件 |
| “r+” | 读扩展 | 打开文件以读/写 | 从头读 | 错误 |
| “w+” | 写扩展 | 创建文件以读/写 | 销毁内容 | 创建新文件 |
| “a+” | 后附扩展 | 打开文件以读/写 | 写到结尾 | 创建新文件 |
- 二进制模式:在文件访问模式字符串后附加
"b"(如"rb"、"wb+")可指定以二进制模式打开文件(仅在 Windows 系统生效)。 - 附加模式特性:在附加模式(
"a"/"a+")下,数据始终写入文件尾部,与文件位置指示器的当前位置无关。 - 更新模式:当模式包含
"+"时(如"r+"、"w+"),允许同时对文件进行读写操作。
30. size_t
size_t是 无符号整数类型,用于表示对象的大小或数组的索引,其具体大小取决于系统架构。
1 | typedef unsigned int size_t; // 32 位系统上 |
| 特点 | size_t |
int |
|---|---|---|
| 是否有符号 | 无符号(不能存负值) | 有符号 |
| 是否平台相关 | ✅ 取决于 32/64 位系统 | ❌ 通常 4 字节(32 位) |
| 主要用途 | 存储大小、数组索引 | 一般整数运算 |
是否用于 sizeof() |
✅ 推荐 | ❌ 不推荐 |
1 |
|
1 |
|
逆序中文/英文字符串
1 |
|
- Title: c review
- Author: KDAIer
- Created at : 2025-03-17 19:07:51
- Updated at : 2025-03-18 14:29:52
- Link: https://kcarnival.cn/2025/03/17/c-review/
- License: All Rights Reserved © KDAIer